Zhen Zhu
Envision the whole of you.
Researcher at Google DeepMind; Ph.D. (CS) UIUC.

Welcome! I’m a currently a researcher at Google DeepMind. I completed my Ph.D. in Computer Science at the University of Illinois at Urbana-Champaign (UIUC), advised by Professor Derek Hoiem. During my PhD, I focused on continual, multimodal, and controllable visual learning. I received my Master’s degree from HUST in June 2020, supervised by Professor Xiang Bai.
Research Focus
- Continual & Dynamic Learning — algorithms that update models in real time without forgetting.
- Multimodal Models — factual and grounded large multimodal models that integrate images, text, video, etc.
- Controllable Synthesis — autoregressive/diffusion-based models for fast, precise and user-directed editing.
- Visual Recognition — models for fundamental visual understanding, such as object detection and segmentation.
Always happy to chat about ideas, research, AI, and collaborations—feel free to reach out.
More about me: CV · Google Scholar
2018
-
Abstract: Object detection is an important and challenging problem in computer vision. Although the past decade has witnessed major advances in object detection in natural scenes, such successes have been slow to aerial imagery, not only because of the huge variation in the scale, orientation and shape of the object instances on the earth’s surface, but also due to the scarcity of well-annotated datasets of objects in aerial scenes. To advance object detection research in Earth Vision, also known as Earth Observation and Remote Sensing, we introduce a large-scale Dataset for Object deTection in Aerial images (DOTA). To this end, we collect 2806 aerial images from different sensors and platforms. Each image is of the size about 4000-by-4000 pixels and contains objects exhibiting a wide variety of scales, orientations, and shapes. These DOTA images are then annotated by experts in aerial image interpretation using 15 common object categories. The fully annotated DOTA images contains 188,282 instances, each of which is labeled by an arbitrary (8 d.o.f.) quadrilateral. To build a baseline for object detection in Earth Vision, we evaluate state-of-the-art object detection algorithms on DOTA. Experiments demonstrate that DOTA well represents real Earth Vision applications and are quite challenging.
-

Abstract: The real world exhibits an abundance of non-stationary textures. Examples include textures with large-scale structures, as well as spatially variant and inhomogeneous textures. While existing example-based texture synthesis methods can cope well with stationary textures, non-stationary textures still pose a considerable challenge, which remains unresolved. In this paper, we propose a new approach for example-based non-stationary texture synthesis. Our approach uses a generative adversarial network (GAN), trained to double the spatial extent of texture blocks extracted from a specific texture exemplar. Once trained, the fully convolutional generator is able to expand the size of the entire exemplar, as well as of any of its sub-blocks. We demonstrate that this conceptually simple approach is highly effective for capturing large-scale structures, as well as other non-stationary attributes of the input exemplar. As a result, it can cope with challenging textures, which, to our knowledge, no other existing method can handle.
-
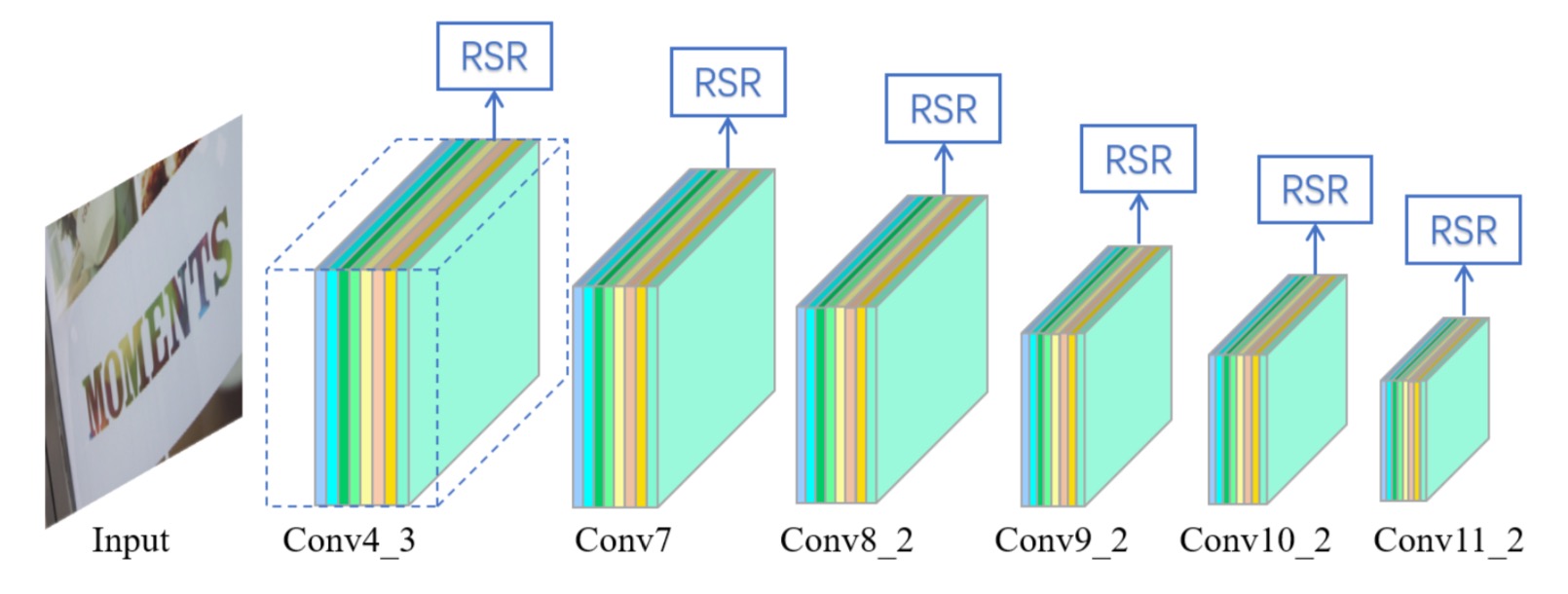
Abstract: Text in natural images is of arbitrary orientations, requiring detection in terms of oriented bounding boxes. Normally, a multi-oriented text detector often involves two key tasks: 1) text presence detection, which is a classification problem disregarding text orientation; 2) oriented bounding box regression, which concerns about text orientation. Previous methods rely on shared features for both tasks, resulting in degraded performance due to the incompatibility of the two tasks. To address this issue, we propose to perform classification and regression on features of different characteristics, extracted by two network branches of different designs. Concretely, the regression branch extracts rotation-sensitive features by actively rotating the convolutional filters, while the classification branch extracts rotation-invariant features by pooling the rotation-sensitive features. The proposed method named Rotation-sensitive Regression Detector (RRD) achieves state-of-the-art performance on three oriented scene text benchmark datasets, including ICDAR 2015, MSRA-TD500, RCTW-17 and COCO-Text. Furthermore, RRD achieves a significant improvement on a ship collection dataset, demonstrating its generality on oriented object detection.

2019
-
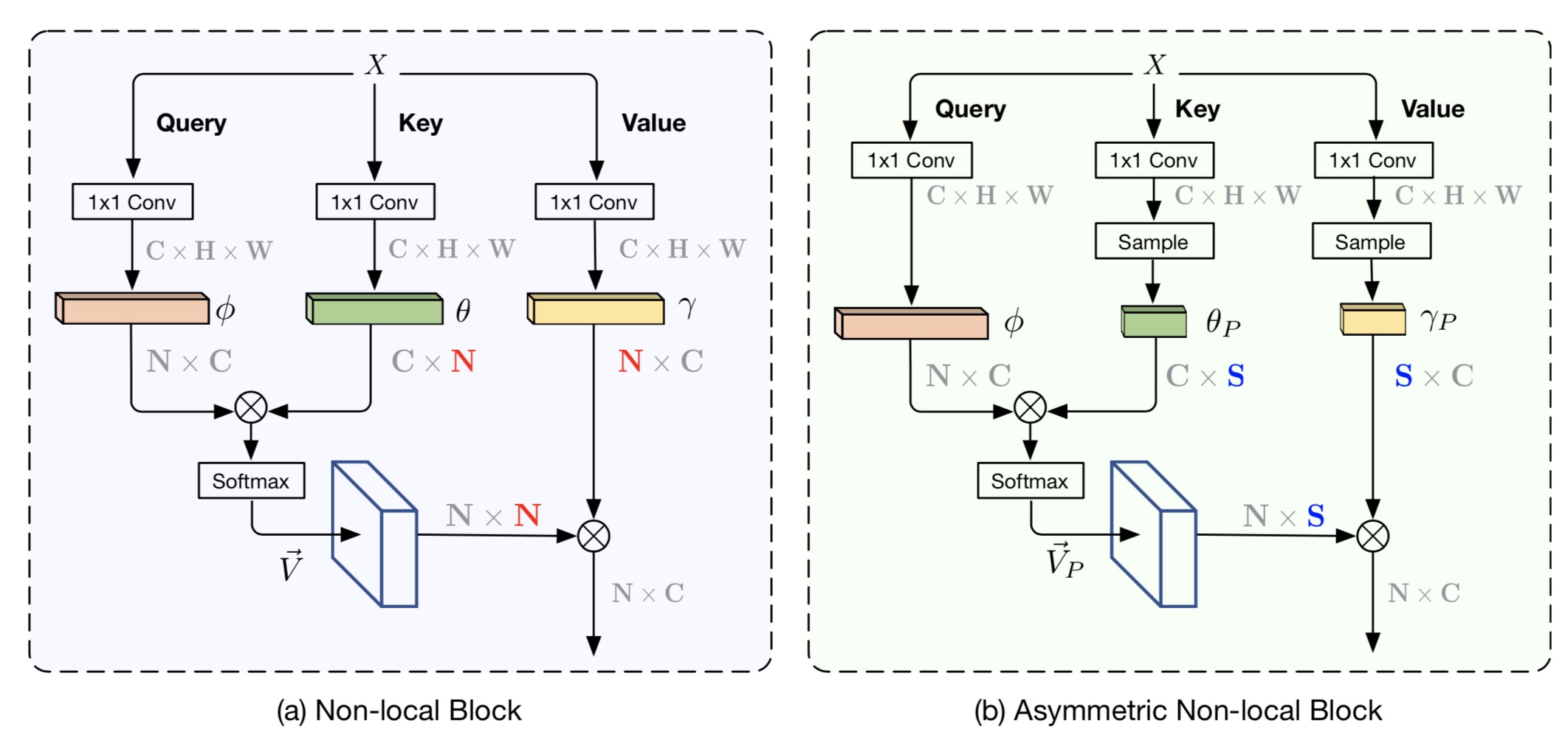
Abstract: The non-local module works as a particularly useful technique for semantic segmentation while criticized for its prohibitive computation and GPU memory occupation. In this paper, we present Asymmetric Non-local Neural Network to semantic segmentation, which has two prominent components: Asymmetric Pyramid Non-local Block (APNB) and Asymmetric Fusion Non-local Block (AFNB). APNB leverages a pyramid sampling module into the non-local block to largely reduce the computation and memory consumption without sacrificing the performance. AFNB is adapted from APNB to fuse the features of different levels under a sufficient consideration of long range dependencies and thus considerably improves the performance. Extensive experiments on semantic segmentation benchmarks demonstrate the effectiveness and efficiency of our work. In particular, we report the state-of-the-art performance of 81.3 mIoU on the Cityscapes test set. For a 256x128 input, APNB is around 6 times faster than a non-local block on GPU while 28 times smaller in GPU running memory occupation.
-
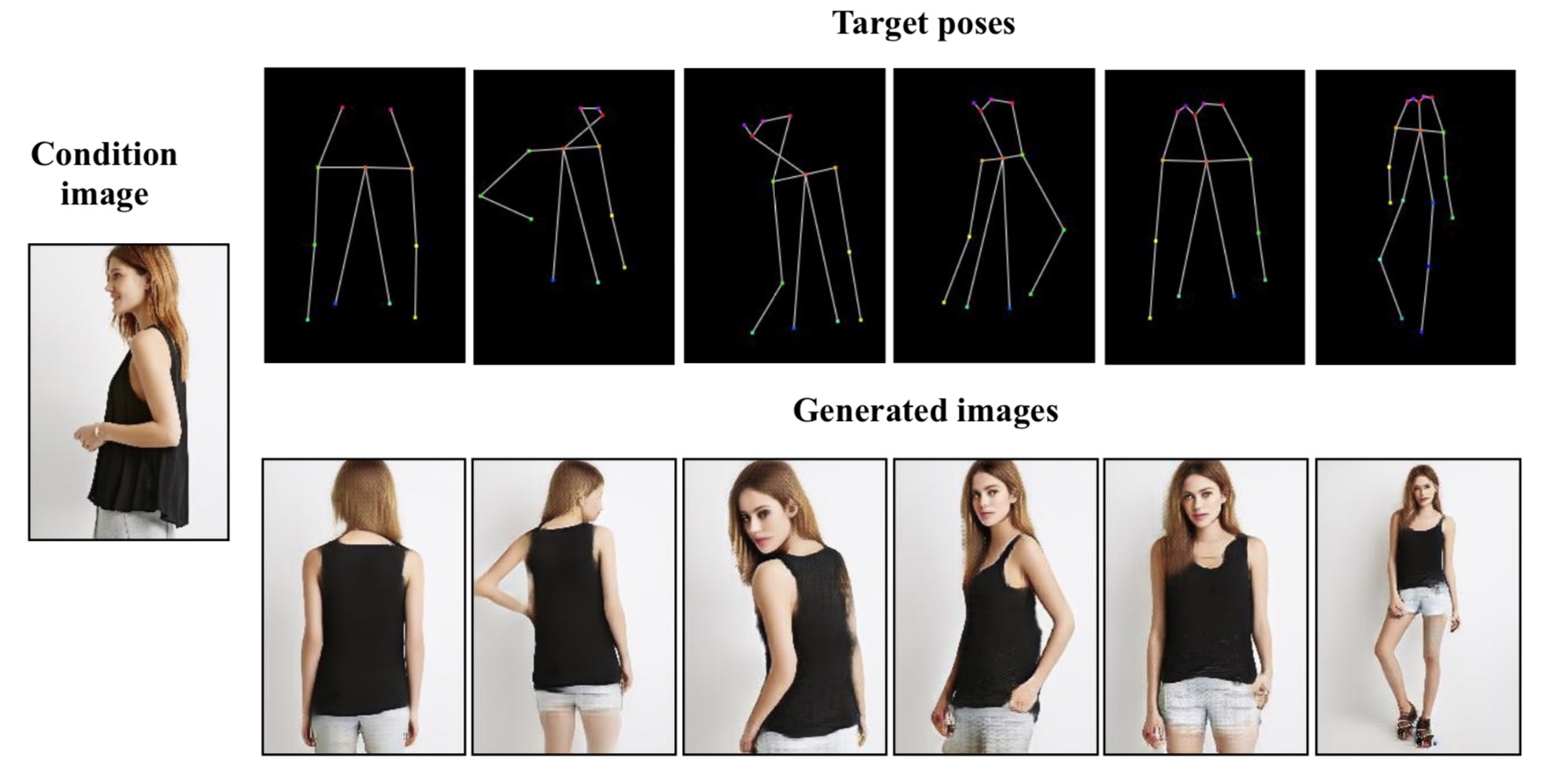
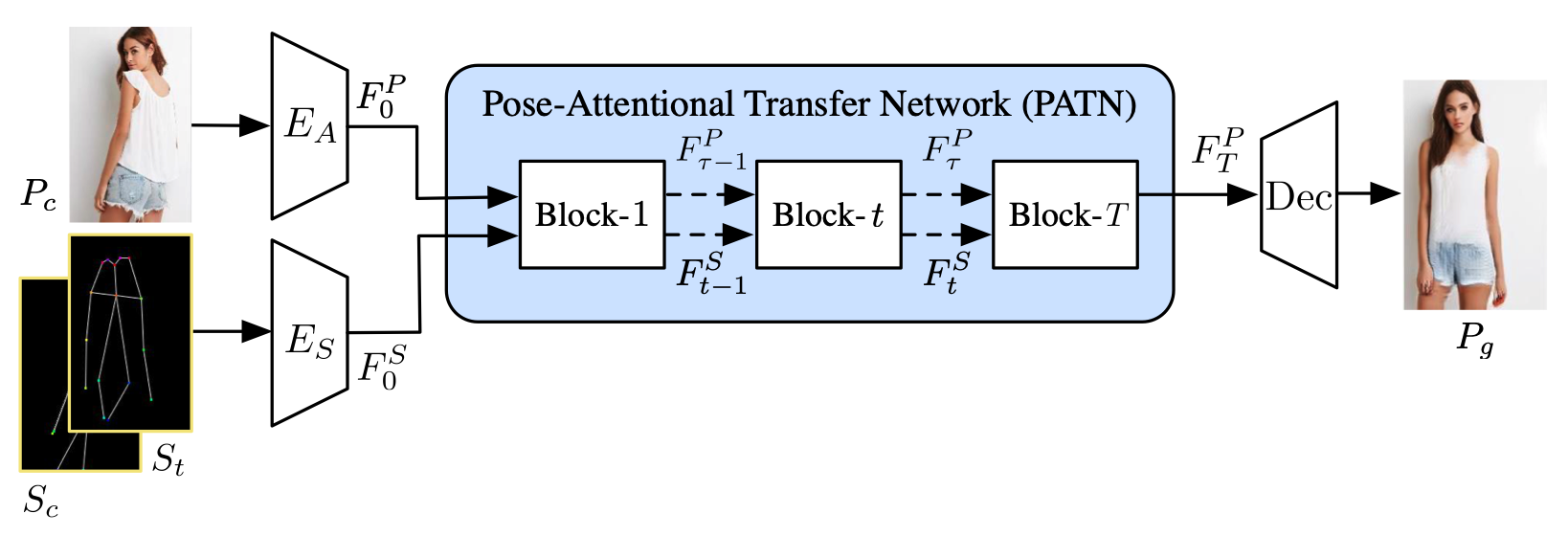
Abstract: This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. The generator of the network comprises a sequence of Pose-Attentional Transfer Blocks that each transfers certain regions it attends to, generating the person image progressively. Compared with those in previous works, our generated person images possess better appearance consistency and shape consistency with the input images, thus significantly more realistic-looking. The efficacy and efficiency of the proposed network are validated both qualitatively and quantitatively on Market-1501 and DeepFashion. Furthermore, the proposed architecture can generate training images for person re-identification, alleviating data insufficiency.
2020
-
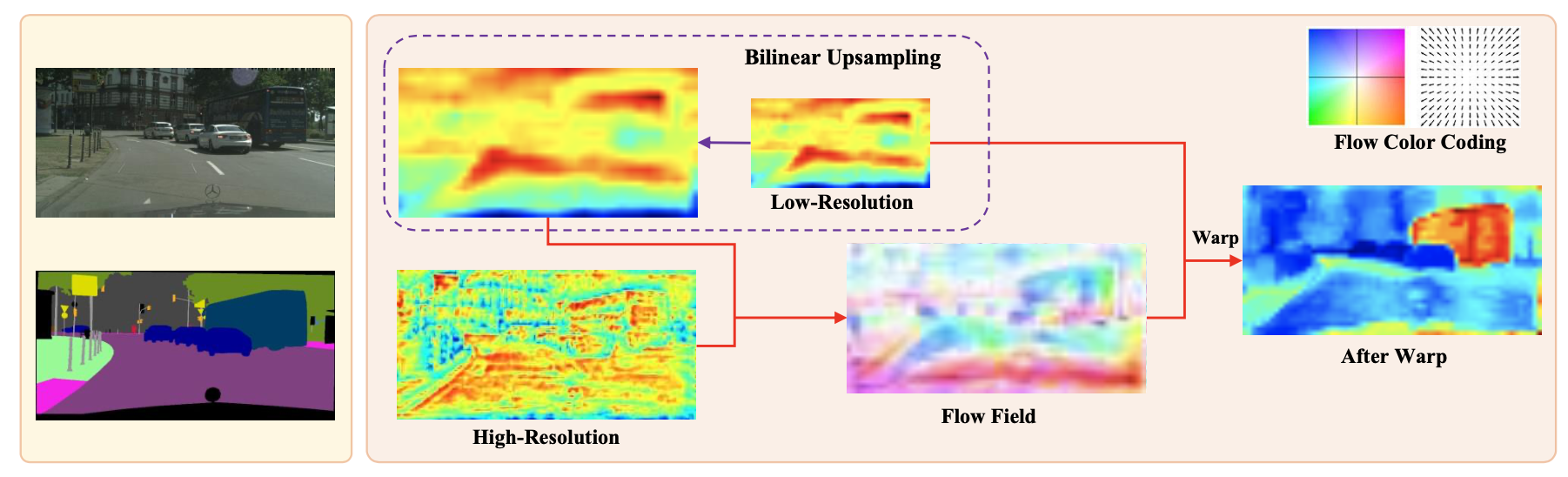
Abstract: In this paper, we focus on designing effective method for fast and accurate scene parsing. A common practice to improve the performance is to attain high resolution feature maps with strong semantic representation. Two strategies are widely used – atrous convolutions and feature pyramid fusion, are either computation intensive or ineffective. Inspired by the Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn Semantic Flow between feature maps of adjacent levels, and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our module to a common feature pyramid structure exhibits superior performance over other real-time methods even on light-weight backbone networks, such as ResNet-18. Extensive experiments are conducted on several challenging datasets, including Cityscapes, PASCAL Context, ADE20K and CamVid. Especially, our network is the first to achieve 80.4% mIoU on Cityscapes with a frame rate of 26 FPS.
-
Abstract: In this paper, we focus on semantically multi-modal image synthesis (SMIS) task, namely, generating multi-modal images at the semantic level. Previous work seeks to use multiple class-specific generators, constraining its usage in datasets with a small number of classes. We instead propose a novel Group Decreasing Network (GroupDNet) that leverages group convolutions in the generator and progressively decreases the group numbers of the convolutions in the decoder. Consequently, GroupDNet is armed with much more controllability on translating semantic labels to natural images and has plausible high-quality yields for datasets with many classes. Experiments on several challenging datasets demonstrate the superiority of GroupDNet on performing the SMIS task. We also show that GroupDNet is capable of performing a wide range of interesting synthesis applications.

2021
-
Abstract: This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. We design a progressive generator which comprises a sequence of transfer blocks. Each block performs an intermediate transfer step by modeling the relationship between the condition and the target poses with attention mechanism. Two types of blocks are introduced, namely Pose-Attentional Transfer Block (PATB) and Aligned Pose-Attentional Transfer Bloc (APATB). Compared with previous works, our model generates more photorealistic person images that retain better appearance consistency and shape consistency compared with input images. We verify the efficacy of the model on the Market-1501 and DeepFashion datasets, using quantitative and qualitative measures. Furthermore, we show that our method can be used for data augmentation for the person re-identification task, alleviating the issue of data insufficiency.
2022
-
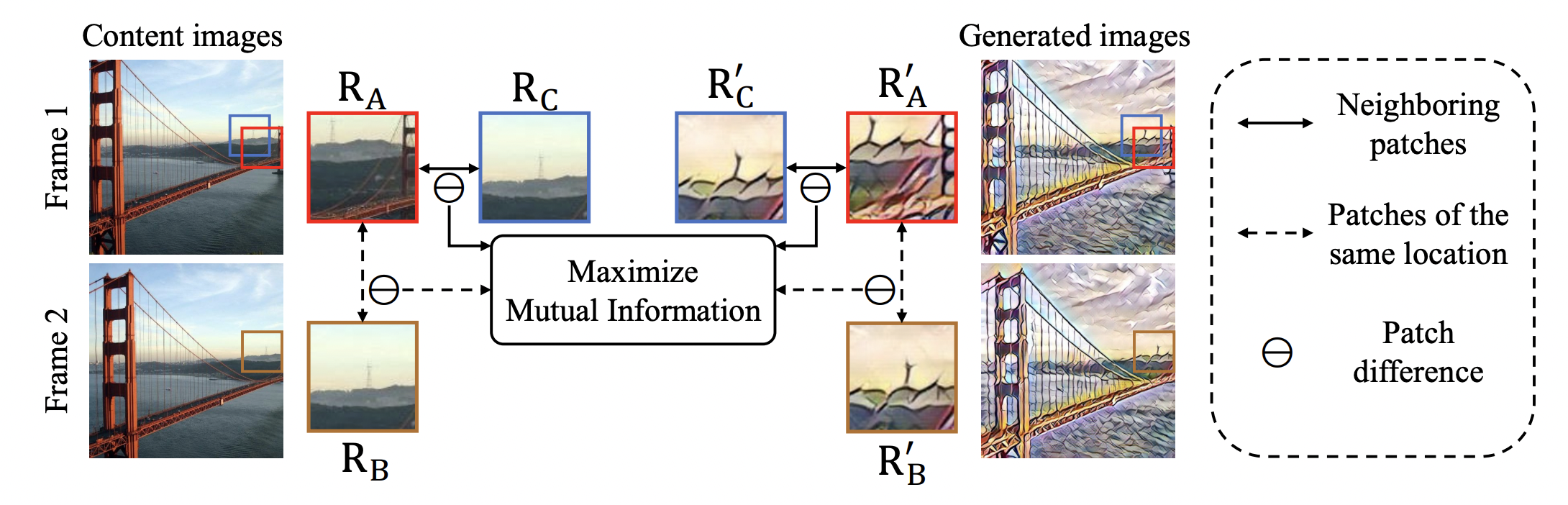
Abstract: In this paper, we aim to devise a universally versatile style transfer method capable of performing artistic, photo-realistic, and video style transfer jointly, without seeing videos during training. Previous single-frame methods assume a strong constraint on the whole image to maintain temporal consistency, which could be violated in many cases. Instead, we make a mild and reasonable assumption that global inconsistency is dominated by local inconsistencies and devise a generic Contrastive Coherence Preserving Loss (CCPL) applied to local patches. CCPL can preserve the coherence of the content source during style transfer without degrading stylization. Moreover, it owns a neighbor-regulating mechanism, resulting in a vast reduction of local distortions and considerable visual quality improvement. Aside from its superior performance on versatile style transfer, it can be easily extended to other tasks, such as image-to-image translation. Besides, to better fuse content and style features, we propose Simple Covariance Transformation (SCT) to effectively align second-order statistics of the content feature with the style feature. Experiments demonstrate the effectiveness of the resulting model for versatile style transfer, when armed with CCPL.
2024
-

Abstract: We propose an approach for anytime continual learning (AnytimeCL) for open vocabulary image classification. The AnytimeCL problem aims to break away from batch training and rigid models by requiring that a system can predict any set of labels at any time and efficiently update and improve when receiving one or more training samples at any time. Despite the challenging goal, we achieve substantial improvements over recent methods. We propose a dynamic weighting between predictions of a partially fine-tuned model and a fixed open vocabulary model that enables continual improvement when training samples are available for a subset of a task’s labels. We also propose an attention-weighted PCA compression of training features that reduces storage and computation with little impact to model accuracy. Our methods are validated with experiments that test flexibility of learning and inference.
-
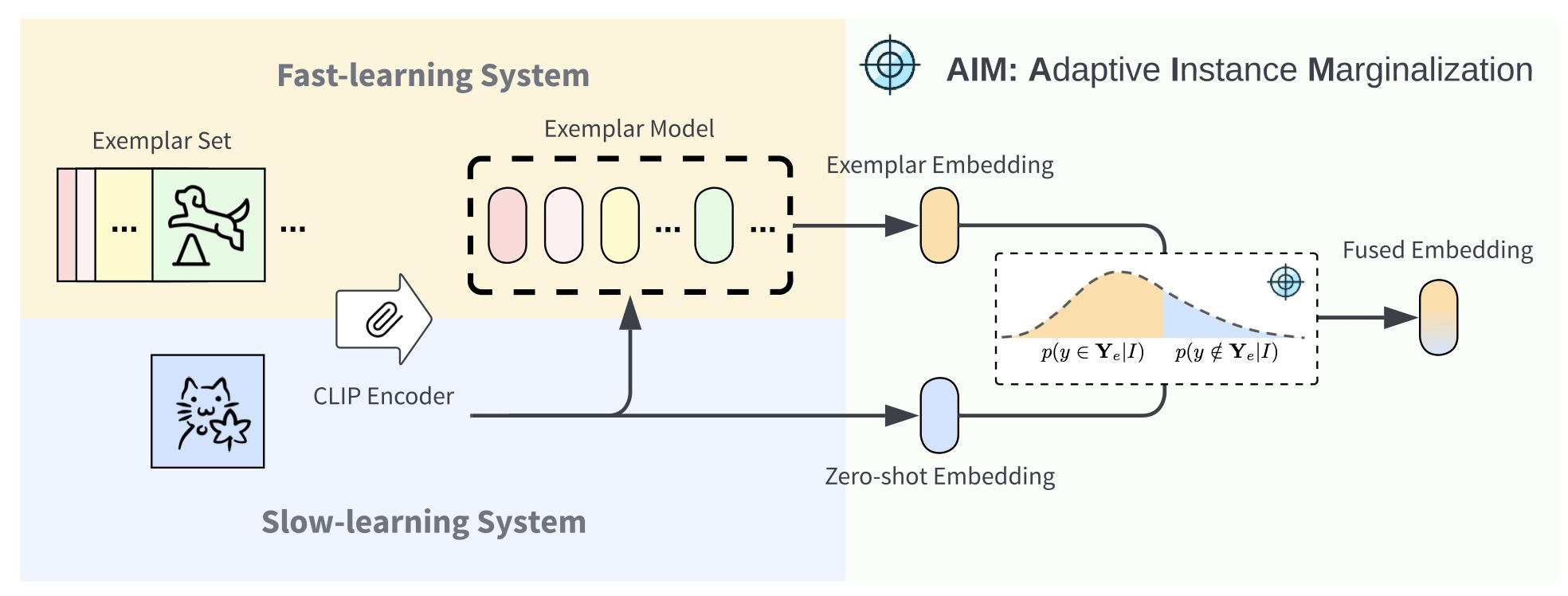
Abstract: We introduce a method for flexible and efficient continual learning in open-vocabulary image classification, drawing inspiration from the complementary learning systems observed in human cognition. Specifically, we propose to combine predictions from a CLIP zero-shot model and the exemplar-based model, using the zero-shot estimated probability that a sample’s class is within the exemplar classes. We also propose a "tree probe" method, an adaption of lazy learning principles, which enables fast learning from new examples with competitive accuracy to batch-trained linear models. We test in data incremental, class incremental, and task incremental settings, as well as ability to perform flexible inference on varying subsets of zero-shot and learned categories. Our proposed method achieves a good balance of learning speed, target task effectiveness, and zero-shot effectiveness.
2025
-
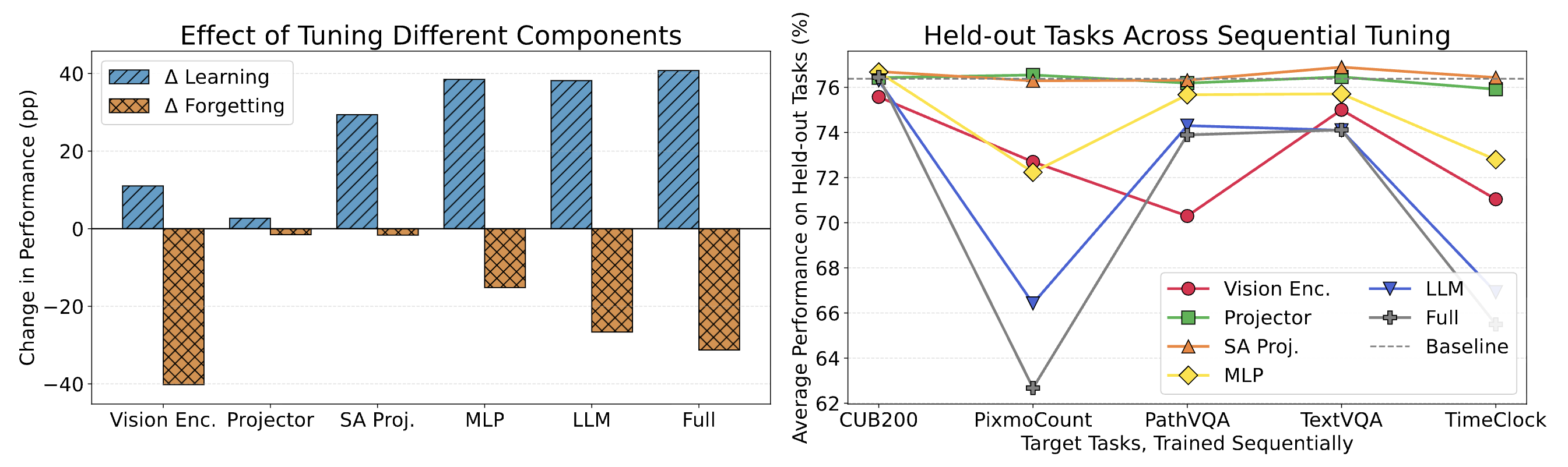
Abstract: How can we teach large multimodal models (LMMs) new skills without erasing prior abilities? We study sequential fine-tuning on five target skills while monitoring general ability on eight held-out benchmarks across three model families. We observe that apparent "forgetting" on held-out tasks after narrow fine-tuning can partly recover at later stages. We trace this behavior to a measurable shift in the output token distribution, manifested through a simple counting-bias probe that co-varies with forgetting. Guided by this picture, we identify two simple, robust tuning recipes that learn strongly while limiting drift: (i) updating only the self-attention projection layers, and (ii) updating only the MLP Gate&Up while freezing the Down projection. Across models and tasks, these choices deliver strong target gains while largely preserving held-out performance.
-
 2025 Under ReviewUnder Review
2025 Under ReviewUnder ReviewAbstract: Image-text models excel at image-level tasks but struggle with detailed visual understanding. While these models provide strong visual-language alignment, segmentation models like SAM2 offer precise spatial boundaries for objects. To this end, we propose TextRegion, a simple, effective and training-free framework that combines the strengths of image-text models and SAM2 to generate powerful text-aligned region tokens. These tokens enable detailed visual understanding while preserving open-vocabulary capabilities. They can be directly applied to various downstream tasks, including open-world semantic segmentation, referring expression comprehension, and grounding. We conduct extensive evaluations and consistently achieve superior or competitive performance compared to state-of-the-art training-free methods. Additionally, our framework is compatible with many image-text models, making it highly practical and easily extensible as stronger models emerge.
-
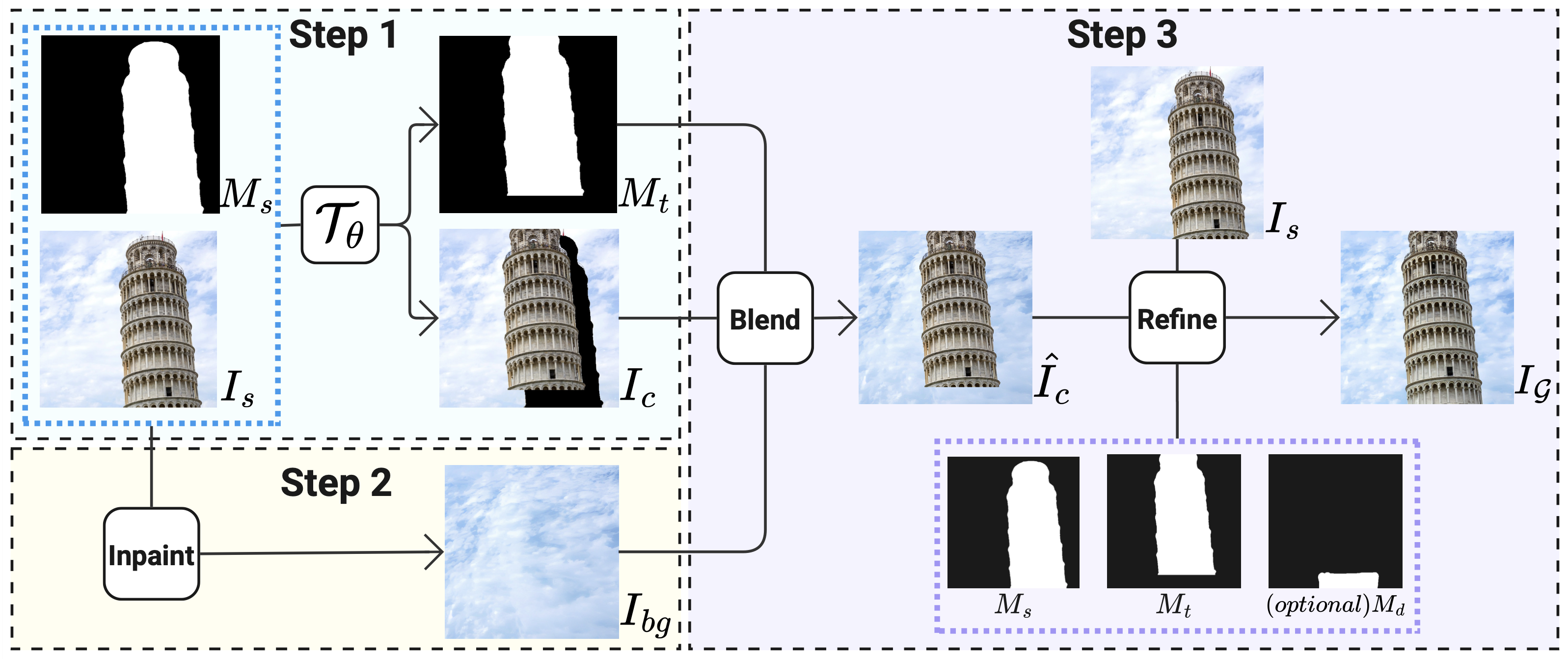
Abstract: We tackle the problem of geometric image editing, where an object within an image is repositioned, reoriented, or reshaped while preserving overall scene coherence. Previous diffusion-based editing methods often attempt to handle all relevant subtasks in a single step, which proves difficult when transformations become large or structurally complex. We address this by proposing a decoupled pipeline that separates object transformation, source region inpainting, and target region refinement. Both inpainting and refinement are implemented using a training-free diffusion approach, FreeFine. In experiments on our new GeoBench benchmark, which contains both 2D and 3D editing scenarios, FreeFine outperforms state-of-the-art alternatives in image fidelity and edit precision, especially under demanding transformations.
Collaborations
I've had the privilege of mentoring several talented students throughout my Ph.D. journey:
- Zhiliang Xu — Image Generation and Face Synthesis
- Yang Liu — Watermark Removal and Image Processing
- Zijie Wu — Style Transfer and Generative Models
- Yiming Gong — Machine Learning and Image Editing
- Joshua Cho — Computational Photography and Image Enhancement
- Xudong Xie — Texture Synthesis
My current close collaborators:
- Yao Xiao — Video Understanding and Multimodal Learning
- Zhipeng Bao — Multimodal Generation
Service
Co-organizer: UIUC External Speaker Series — Interested speakers are welcome to reach out to register for upcoming sessions
Co-organizer: UIUC Vision Mini-Conference
Conference Reviewer: CVPR, ICCV, ECCV, ICLR, NeurIPS, ICML, AAAI, IJCAI, BMVC, WACV, and others
Journal Reviewer: TPAMI, IJCV, TIP, PR, and others